Why Math is hard (even if you are an AI)
Some people rely on LLMs to perform mathematical operations. This approach does not work

Many people also rely on LLMs to perform mathematical operations. This approach doesn’t work.
The issue is actually quite simple: large language models (LLMs) don’t really know how to multiply. They may sometimes guess the correct answer, just as I might know the value of pi by heart. But that doesn’t mean I’m a mathematician, nor does it mean that LLMs actually know how to do math.
Practical example
Example: 49858 * 5994949 = 298896167242 This result is always the same; there is no middle ground. It is either correct or incorrect.
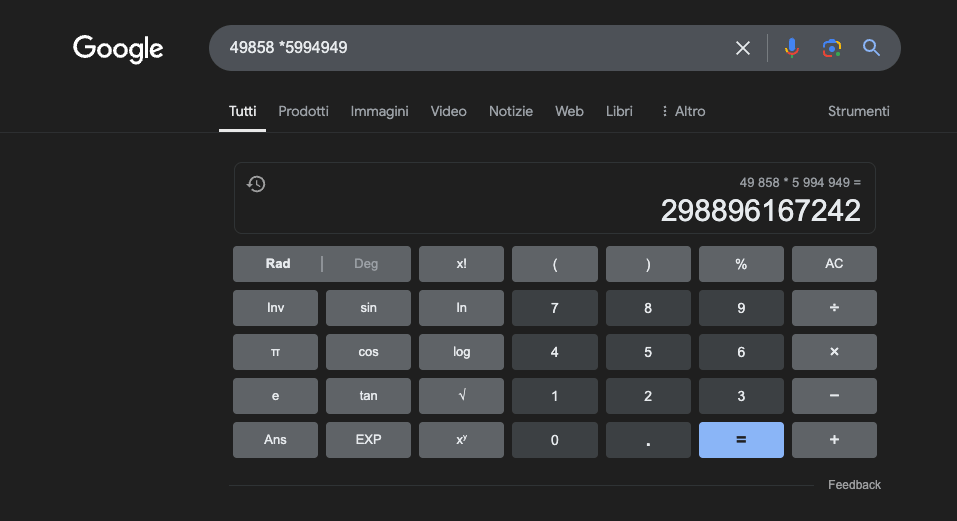
Even with extensive training focused on math, the best models can only solve a portion of the operations correctly. A simple pocket calculator, on the other hand, gets 100% of the results correct, every time. And the larger the numbers get, the worse LLMs perform.
Is it possible to solve this problem?
The underlying problem is that these models learn by similarity, not by understanding. They work best with problems similar to those they were trained on, but they never develop a true understanding of what they’re stating.
For those who want to learn more, I recommend this article on “how an LLM works”.
A calculator, on the other hand, uses a precise algorithm programmed to perform the mathematical operation.
This is why we should never rely entirely on LLMs for mathematical calculations: even under the best conditions, with massive amounts of specific training data, they cannot guarantee reliability even in the most basic operations. A hybrid approach might work, but LLMs alone are not sufficient. Perhaps this approach will be adopted to solve the so-called “strawberry problem” (The Strawberry Problem).
Applications of LLMs in the Study of Mathematics
In an educational context, LLMs can serve as personalized tutors, capable of adapting explanations to the student’s level of understanding. For example, when a student tackles a differential calculus problem, the LLM can break down the reasoning into simpler steps, providing detailed explanations for each stage of the solution process. This approach helps build a solid understanding of fundamental concepts.
A particularly interesting aspect is the ability of LLMs to generate relevant and varied examples. If a student is trying to understand the concept of a limit, the LLM can present various mathematical scenarios, starting with simple cases and progressing to more complex situations, thereby enabling a gradual understanding of the concept.
A promising application is the use of LLMs to translate complex mathematical concepts into more accessible natural language. This facilitates the communication of mathematics to a broader audience and can help overcome the traditional barrier to entry into this discipline.
LLMs can also assist in the preparation of instructional materials, generating exercises of varying difficulty and providing detailed feedback on the solutions proposed by students. This allows teachers to better personalize their students’ learning paths.
The Real Advantage
It is also worth considering, more generally, the extreme “patience” in helping even the least “capable” students learn: in this case, the absence of emotions helps. Despite this, even AI sometimes “loses its patience.” See this “amusing” example.
2025 Update: Reasoning Models and the Hybrid Approach
The 2024–2025 period brought significant developments with the arrival of so-called “reasoning models” such as OpenAI’s o1 and deepseek’s R1. These models have achieved impressive results on mathematical benchmarks: o1 correctly solves 83% of AIMO problems, compared to 13% for GPT-4o. But beware: they have not solved the fundamental problem described above.
The strawberry problem—counting the ‘r’s in “strawberry”—perfectly illustrates this persistent limitation. o1 solves it correctly after a few seconds of “reasoning,” but if you ask it to write a paragraph where the second letter of each sentence spells out the word “CODE,” it fails. o1-pro, the $200-per-month version, solves it... after 4 minutes of processing. DeepSeek R1 and other recent models still get the basic count wrong. In February 2025, Mistral continued to respond that there are only two 'r's in “strawberry.”
The emerging trick is the hybrid approach: when they have to multiply 49,858 by 5,994,949, the most advanced models no longer try to “guess” the result based on similarities to calculations seen during training. Instead, they call up a calculator or run Python code—exactly as an intelligent human who knows their own limits would do.
This “tool use” represents a paradigm shift: artificial intelligence doesn’t have to know how to do everything on its own, but it must know how to orchestrate the right tools. Reasoning models combine linguistic ability to understand the problem, step-by-step reasoning to plan the solution, and delegation to specialized tools (calculators, Python interpreters, databases) for precise execution.
The lesson? The LLMs of 2025 are more useful in mathematics not because they have “learned” to multiply—they haven’t really done that yet—but because some of them have begun to understand when to delegate multiplication to those who can actually do it. The underlying problem remains: they operate based on statistical similarity, not algorithmic understanding. A $5 calculator remains infinitely more reliable for precise calculations.
Revision note, June 2026 — Original article from 2024, updated in early 2025 with the section on reasoning models, and revised now to correct a reference: o1’s 83% benchmark is the AIME, the American International Math Exam, not the International Mathematical Olympiad. Meanwhile, in July 2025, models from OpenAI and Google DeepMind achieved gold-level performance at the IMO itself. The argument still holds: they have become competitive mathematicians, not calculators. For arithmetic precision, they rely on a tool—and that is precisely the point of the article.



Comments ()